Jenkins cheat-sheet
This is just a set of tools and info that I find usefull to gather here for future reference.
Jenkins installation in an EC2 instance using Amazon Linux 2
Getting the repo
sudo sudo amazon-linux-extras install java-openjdk11 -y
sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat/jenkins.repo
sudo rpm --import https://pkg.jenkins.io/redhat/jenkins.io.key
sudo yum install jenkins -y
Starting the jenkins service
sudo service jenkins start
sudo chkconfig jenkins on
Also, in case you want to test, stop or restart the jenkins service then use:
sudo service jenkins restart
sudo service jenkins stop
sudo service jenkins status
Location of the initial Jenkins user password
To retrieve the initial admin password necessary in the Jenkins installation, in the case of a unix system:
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
Starting Jenkins 1: Jenkins port
To start using Jenkins, you need to be sure of which port is using the jenkins service:
sudo cat /etc/sysconfig/jenkins | grep JENKINS_PORT
Normally it should be port 8080. If another service is using the same port as Jenkins, we can modify the value of JENKINS_PORT
to a port which is not used.
In case you want to test which ports are opened, and which services are listening to them:
sudo netstat -tulpn | grep LISTEN
Starting Jenkins 2: Using Jenkins installed in an EC2 instance
IMPORTANT: It is necessary to add a rule to the security group of the EC2 instance hosting Jenkins. The rule should allow custom tcp (TCP personalizada in Spanish) traffic type,
allowing traffic from the IP range needed in your case (origin) through the JENKINS_PORT value.
Starting Jenkins 3: finish Jenkins installation using the web browser
Now you should be able to open Jenkins. You need to navigate to http://localhost:JENKINS_PORT in the case that you installed Jenkins on your PC, or to http://public IP:JENKINS_PORT if it is installed in a remote host. As it should be in the case of Jenkins hosted on an EC2 instance. In this case you can retrieve the value of the public IP or public DNS from the console, or using the shell:
PUBLIC_IP=$(curl -s ifconfig.co)
echo $PUBLIC_IP
I found useful to create an alias which prints out Jenkins address, including the following line at the end of /home/ec2-user/.bashrc :
alias showJenkinsURL='dum=\$(curl -s ifconfig.co);echo http://\${dum}:8080'
so that, a possible output could be:
$ showJenkinsURL
http://102.321.21.3:8080
The motivation of this alias is the following: every time an EC2 instance is stopped, the public IP is lost; when the instance is restarted, the data is still there, you will find the same jobs and pipelines, but a new public IP will be associated. With this command it is easy to retrieve the Jenkins url everytime you ssh access the EC2 instance after it is restarted.
Once you navigate to your Jenkins url, you must introduce the initial admin password retrieved in a former step. Accept the default plugin installation or customize your choice, enter an admin username and password, and after that you are ready to use Jenkins.
Jenkins agent
Jenkins configures a unix user, called service user, which doesn’t have a shell associated. To login to the jenkins user run:
sudo su -s /bin/bash jenkins
Jenkins creates a folder per job or pipeline in:
/var/lib/jenkins/workspace
you can check the root directory of Jenkins in Control Panel -> Configuration http://publicIP:JENKINS_PORT/configure.
It is possible to add Jenkins environment variables to the existing ones in http://publicIP:JENKINS_PORT/configure. This variables are shared among jobs and can be used by pipeline scripts as normal unix environment variables. Check the Jenkins environment variables in:
- http://localhost:8080/env-vars.html
- http://publicIP:JENKINS_PORT/env-vars.html
Add jenkins to the sudoers:
As root edit the file /etc/sudoers appending the line
jenkins ALL=(ALL) NOPASSWD: ALL
Jenkins and ssh keys
You might need Jenkins to connect to remote hosts, e.g., when running Ansible playbooks. In that case, you need to have the necessary ssh key pair.
The keys must be located in /var/lib/jenkins/.ssh.
Create a pipeline
Pipelines are a useful tool provided by Jenkins which allows to configure a series of tasks using code. There are two ways to build a pipeline script:
- Scripted pipeline using Groovy
- Declarative pipeline using Jenkins DSL
Let us discuss declarative pipelines since they are fairly simple. A declarative pipeline would have the structure
pipeline {
agent any
environment {
TFPROJECTFOLDER = 'terraform-demo'
TFPROJECTREPO = 'https://github.com/.../terraform-demo.git'
}
stages {
stage('Clone templates') {
steps {
sh '''#!/bin/bash
mkdir -p ${TF_WORKSPACE_PATH}
cd ${TF_WORKSPACE_PATH}
exists=$(ls ${TFPROJECTFOLDER} 2>/dev/null)
if [ -z $exists ]
then
git clone ${TFPROJECTREPO}
else
cd ${TF_WORKSPACE_PATH}/${TFPROJECTFOLDER}
git checkout main
git fetch --all
git reset --hard origin/main
fi
'''
}
}
stage('Terraform init') {
steps {
sh '''#!/bin/bash
cd ${TF_WORKSPACE_PATH}/${TFPROJECTFOLDER};
terraform init;
'''
}
}
stage('Terraform apply') {
steps {
sh '''#!/bin/bash
cd ${TF_WORKSPACE_PATH}/${TFPROJECTFOLDER};
terraform apply -auto-approve
'''
}
}
stage('Terraform refresh') {
steps {
sh '''#!/bin/bash
cd ${TF_WORKSPACE_PATH}/${TFPROJECTFOLDER};
terraform refresh
'''
}
}
}
}
As we see, there is a root block called pipeline, and inside there are two more structures:
- environment: contains environment variables used inside the pipeline script
- stages: contains the different stages or block of steps
- stage: it is a well defined block of tasks or
stepswith a specific purpose- step: contains an shell script to be executed on the host managed by the jenkins agent
Note that the structure of stages declared above will be translated in the following in Jenkins after running the pipeline.
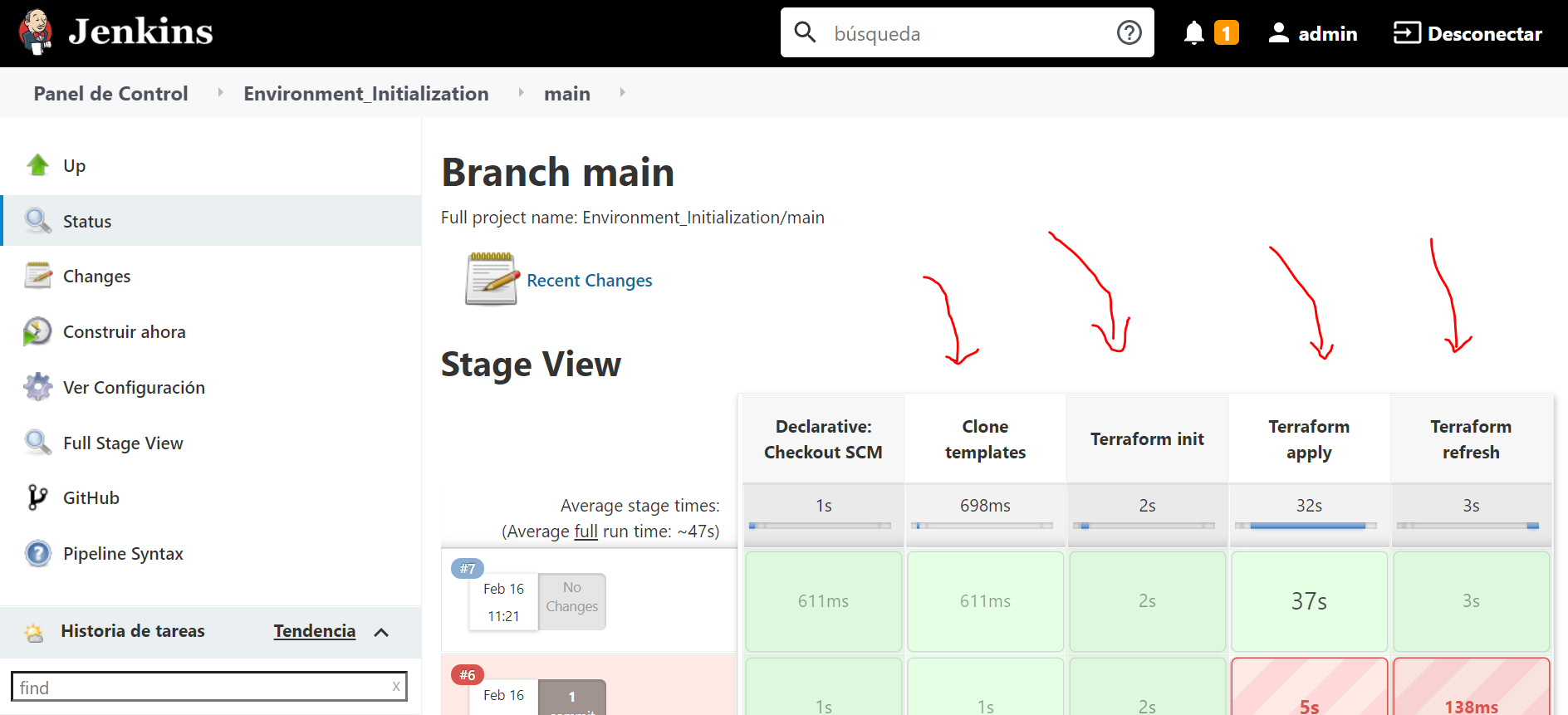
- step: contains an shell script to be executed on the host managed by the jenkins agent
Note that the structure of stages declared above will be translated in the following in Jenkins after running the pipeline.
- stage: it is a well defined block of tasks or
In my experience automating the implementation of Terraform templates with Jenkins Pipelines, if Jenkins and Terraform are installed in the same host, I found useful giving instructions to the jobs/pipelines for creating a workspace folder to store the .tf project as follows
/var/lib/jenkins/workspaces/terraform-workspaces
so that jobs/pipelines managing Terraform ressources would clone the repositories containing the templates inside the former folder:
/var/lib/jenkins/workspaces/terraform-workspaces/TF_PIPELINE_REPOSITORY
and refer to it for their tasks. In this way, the .tfstate file will be the same for all pipelines related to each Terraform repository if well configured.
Note that any environment variable that the jenkins service user needs when running the pipelines must be declared in Jenkins.
Declarative pipeline with script hosted in github
- Create a new pipeline project, give it a name, and select “multibranch pipeline” type.
- On the “branch source” section, introduce the url of your github project where the pipeline script is stored. For test purposes I have only explored using a public repository as code source in this step, to get rid of credentials.
- Select the branch that Jenkins must explore. In Behaviours leave Discover branches with the option “Exclude branches that are also filed as PRs” to omit new branches. I found useful to identify the specific branch that we want by the name, adding
- Filter by name (with wildcards)
to the Behaviours section.
And setting it to the name of the branch (e.g, “main”).
In Build configuration edit Script path to match the path of the desired pipeline script inside the repository:
 This is useful if you want to have multiple declarative pipelines in the same github repository. The
This is useful if you want to have multiple declarative pipelines in the same github repository. The Jenkinsfile’s will be stored in different folders. If you don’t want Jenkins to build the job after scanning the repository, in Property strategy add the property - Suppress automatic SCM triggering
- Filter by name (with wildcards)
to the Behaviours section.
And setting it to the name of the branch (e.g, “main”).
In Build configuration edit Script path to match the path of the desired pipeline script inside the repository:
- Leave the rest of options as default (if you want) and finish clicking OK.
Jenkins will start searching the pipeline script on the path given. You can manually trigger the repository scan. Once you “build” the job, Jenkins will clone the Jenkinsfile into the pipeline workspace inside
/var/lib/jenkins/workspaces/**pipelineworkspace**/**repository**
and it will start performing the steps therein.
Declarative pipeline of scheduled jobs
You can set the jobs to be built on specific times or frequencies. For this, you need to provide the time choices in the CRON syntax. Add the following code to the pipeline:
pipeline {
. . .
triggers {
cron('*/2 * * * *')
}
. . .
stages {
. . .
}
}
where in the example above the pipeline will be triggered every 2 minutes. The CRON syntax is:
Minute Hour DayInMonth Month DayInWeek
So, for example, to trigger the pipeline every saturday and sunday at 19.06 the syntax would be:
triggers {
cron('6 19 * * 6,7')
}
Return to main page